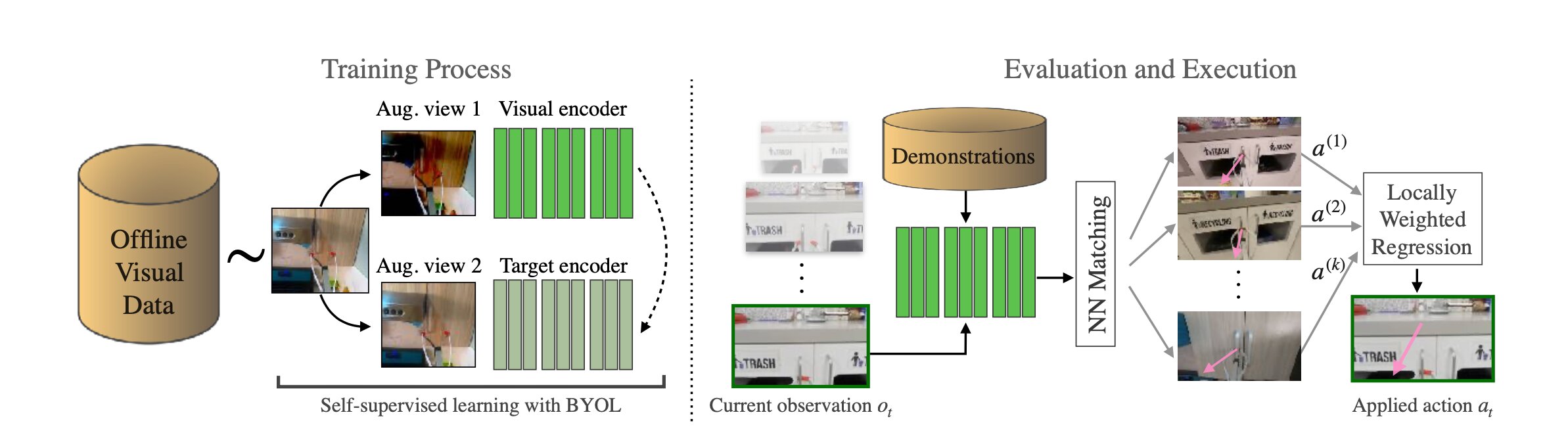

Figure showing the two ‘halves’ of the researchers’ method, with representation learning on the left and behavior imitation through nearest neighbors on the right. Credit: Pari et al.
Over the past few decades, computer scientists have been trying to train robots to tackle a variety of tasks, including house chores and manufacturing processes. One of the most renowned strategies used to train robots on manual tasks is imitation learning.
As suggested by its name, imitation learning entails teaching a robot how to do something using human demonstrations. While in some studies this training strategy achieved very promising results, it often requires large and annotated datasets containing hundreds of videos where humans complete a given task.
Researchers at New York University have recently developed VINN, an alternative imitation learning framework that does not necessarily require large training datasets. This new approach, presented in a paper pre-published on arXiv, works by decoupling two different aspects of imitation learning, namely learning a task’s visual representations and the associated actions.
“I was interested in seeing how we can simplify imitation learning,” Jyo Pari, one of the researchers who carried out the study, told TechXplore. “Imitation learning requires two fundamental components; one is learning what is relevant in your scene and the other is how you can take the relevant features to perform a task. We wanted to decouple these components, which are traditionally coupled into one system, and understand the role and importance of each of them.”
Most existing imitation learning methods combine representation and behavior learning into a single system. The new technique created by Pari and his colleagues, on the other hand, focuses on representation learning, the process through which AI agents and robots learn to identify task-relevant features in a scene.
“We employed existing methods in self-supervised representation learning which is a popular area in the vision community,” Pari explained. “These methods can take a collection of images with no labels and extract the relevant features. Applying these methods to imitation is effective because we can identify which image in the demonstration dataset is most similar that the robot currently sees through a simple nearest neighbor search on the representations. Therefore, we can just make the robot copy the actions from similar demonstration images.”
Using the new imitation learning strategy they developed, Pari and his colleagues were able to enhance the performance of visual imitation models in simulated environments. They also tested their approach on a real robot, efficiently teaching it how to open a door by looking at similar demonstration images.
“I feel that our work is a foundation for future works that can utilize representation learning to enhance imitation learning models,” Pari said. “However, even if our methods were able to conduct a simple nearest neighbor task, they still have some drawbacks.”
In the future, the new framework could help to simplify imitation learning processes in robotics, facilitating their large-scale implementation. So far, Pari and his colleagues only used their strategy to train robots on simple tasks. In their next studies, they thus plan to explore possible strategies that would allow them to implement it on more complex tasks.
“Figuring out how to utilize the nearest neighbor’s robustness on more complex task with the capacity of parametric models is an interesting direction,” Pari added. “We are currently working on scaling up VINN to be able to not only do one task but multiple different ones.”
An imitation learning approach to train robots without the need for real human demonstrations
Jyothish Pari, Nur Muhammad Shafiullah, Sridhar Pandian Arunachalam, Lerrel Pinto, The surprising effectiveness of representation learning for visual imitation. arXiv:2112.01511v2 [cs.RO], arxiv.org/abs/2112.01511
© 2022 Science X Network
Citation:
A new framework that could simplify imitation learning in robotics (2022, January 14)
retrieved 14 January 2022
from https://techxplore.com/news/2022-01-framework-imitation-robotics.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.














