3D object detection from visual information is a difficult task for low-cost autonomous driving systems.

A prototype of an unmanned car. Precision of object detection is crucially important for such type of transport. Image credit: BP63Vincent via Wikimedia, CC-BY-SA-3.0
Most current methods build the detection pipelines purely from 2D computations without considering the 3D scene structure or sensor configuration. A recent paper proposes a smoother transition between 2D observations and 3D predictions.
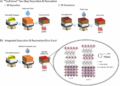
Proposed solution for object detection in 3D space
The researchers propose to link them via geometric back-projection to retrieve image features as needed. Information from all the camera views is fused in each layer of computation and projected onto all available frames.
The suggested architecture does not perform point cloud reconstruction or explicit depth prediction from images, making it robust to errors in the depth estimation. In the camera overlap regions, the proposed method outperforms others by a substantial margin.
We introduce a framework for multi-camera 3D object detection. In contrast to existing works, which estimate 3D bounding boxes directly from monocular images or use depth prediction networks to generate input for 3D object detection from 2D information, our method manipulates predictions directly in 3D space.
Our architecture extracts 2D features from multiple camera images and then uses a sparse set of 3D object queries to index into these 2D features, linking 3D positions to multi-view images using camera transformation matrices. Finally, our model makes a bounding box prediction per object query, using a set-to-set loss to measure the discrepancy between the ground-truth and the prediction.
This top-down approach outperforms its bottom-up counterpart in which object bounding box prediction follows per-pixel depth estimation, since it does not suffer from the compounding error introduced by a depth prediction model. Moreover, our method does not require post-processing such as non-maximum suppression, dramatically improving inference speed. We achieve state-of-the-art performance on the nuScenes autonomous driving benchmark.
Research paper: Wang, Y., Guizilini, V., Zhang, T., Wang, Y., Zhao, H., and Solomon, J., “DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries”, 2021. Link: https://arxiv.org/abs/2110.06922