-
Table of Contents
- Introduction
- What is Random Forest Regression and How Does it Work?
- The Potential of Random Forest Regression for Automated Decision Making
- Investigating the Use of Random Forest Regression for Image Recognition
- Examining the Limitations of Random Forest Regression
- Applying Random Forest Regression to Natural Language Processing
- The Use of Random Forest Regression for Anomaly Detection
- Investigating the Impact of Outliers on Random Forest Regression
- Leveraging Random Forest Regression for Feature Selection
- Optimizing Random Forest Regression for Improved Predictive Accuracy
- Utilizing Random Forest Regression for Time Series Forecasting
- Analyzing the Performance of Random Forest Regression
- How to Implement Random Forest Regression in Python
- Understanding the Hyperparameters of Random Forest Regression
- Comparing Random Forest Regression to Other Machine Learning Algorithms
- The Benefits of Random Forest Regression for Machine Learning Prediction
- Conclusion
“Unlock the Power of Random Forest Regression: Accurate Predictions with Ensemble Learning!”
Introduction
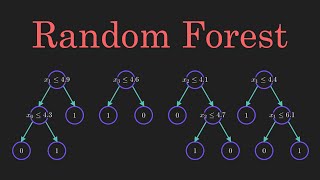
Random Forest Regression is an ensemble learning method for machine learning prediction. It is a supervised learning algorithm that combines multiple decision trees to create a more accurate and stable prediction model. It is a powerful tool for both regression and classification problems. Random Forest Regression is an effective way to reduce overfitting and improve the accuracy of predictions. It is also a great tool for feature selection and can be used to identify important features in a dataset. Random Forest Regression is a powerful and versatile machine learning technique that can be used to solve a variety of problems.
What is Random Forest Regression and How Does it Work?
Random Forest Regression is a supervised machine learning algorithm that is used for regression tasks. It is an ensemble method that combines multiple decision trees to create a more accurate and stable prediction.
The algorithm works by randomly selecting a subset of features from the dataset and then building a decision tree based on those features. This process is repeated multiple times, each time with a different subset of features. The predictions from each tree are then combined to form a single prediction.
The main advantage of Random Forest Regression is that it reduces the variance of the model, making it more robust and less prone to overfitting. It also helps to reduce the complexity of the model, making it easier to interpret.
Random Forest Regression is a powerful tool for regression tasks and can be used to make accurate predictions. It is also relatively easy to implement and can be used with a variety of datasets.
The Potential of Random Forest Regression for Automated Decision Making
Random Forest Regression (RFR) is a powerful machine learning technique that has the potential to revolutionize automated decision making. RFR is an ensemble method that combines multiple decision trees to create a more accurate and robust prediction model. It is a supervised learning algorithm that can be used for both regression and classification tasks.
RFR has several advantages over traditional regression methods. It is highly accurate and can handle large datasets with high dimensionality. It is also robust to outliers and can handle missing data. Additionally, RFR is relatively easy to implement and can be used to make predictions on unseen data.
RFR has been used in a variety of applications, including medical diagnosis, credit scoring, and stock market prediction. In medical diagnosis, RFR can be used to predict the likelihood of a patient developing a certain disease based on their medical history. In credit scoring, RFR can be used to predict the likelihood of a customer defaulting on a loan. In stock market prediction, RFR can be used to predict the future price of a stock.
RFR has the potential to revolutionize automated decision making. It is a powerful and accurate tool that can be used to make predictions on unseen data. Additionally, it is robust to outliers and can handle large datasets with high dimensionality. As such, RFR is an ideal tool for automated decision making.
Investigating the Use of Random Forest Regression for Image Recognition
Image recognition is a rapidly growing field of research, with applications ranging from facial recognition to medical imaging. In recent years, the use of machine learning algorithms has become increasingly popular for image recognition tasks. One such algorithm is Random Forest Regression (RFR), which is a supervised learning technique that can be used to classify images.
RFR is a type of ensemble learning algorithm, which combines multiple decision trees to create a more accurate prediction. Each decision tree is trained on a different subset of the data, and the final prediction is based on the average of the predictions from each tree. This approach is advantageous because it reduces the risk of overfitting, which is when a model is too closely tailored to the training data and does not generalize well to new data.
RFR has been used in a variety of image recognition tasks, including object detection, facial recognition, and medical imaging. In object detection, RFR can be used to identify objects in an image, such as cars, people, or animals. In facial recognition, RFR can be used to identify individuals in an image. In medical imaging, RFR can be used to detect abnormalities in medical scans.
RFR has several advantages over other machine learning algorithms. It is relatively easy to implement, and it is computationally efficient. Additionally, it is robust to outliers and can handle large datasets. Furthermore, it is less prone to overfitting than other algorithms, which makes it well-suited for image recognition tasks.
Overall, Random Forest Regression is a powerful tool for image recognition tasks. It is relatively easy to implement, computationally efficient, and robust to outliers. Additionally, it is less prone to overfitting than other algorithms, which makes it well-suited for image recognition tasks. As such, RFR is an attractive option for researchers looking to develop image recognition systems.
Examining the Limitations of Random Forest Regression
Random Forest Regression is a powerful machine learning algorithm that can be used to make predictions and classify data. However, like all machine learning algorithms, it has certain limitations that should be taken into consideration when using it.
One of the main limitations of Random Forest Regression is its lack of interpretability. Unlike linear regression, which can be used to identify the relationship between different variables, Random Forest Regression is a black box algorithm that does not provide any insight into the underlying relationships between variables. This makes it difficult to understand why the algorithm is making certain predictions and can limit its usefulness in certain applications.
Another limitation of Random Forest Regression is its sensitivity to hyperparameters. Hyperparameters are the parameters that control the behavior of the algorithm, such as the number of trees in the forest and the maximum depth of each tree. If these parameters are not set correctly, the algorithm may not perform as expected. This can be a time-consuming process, as it requires trial and error to find the optimal settings.
Finally, Random Forest Regression can be computationally expensive. The algorithm requires a large amount of data to be processed, which can take a significant amount of time and resources. This can be a problem for applications that require real-time predictions or require the algorithm to be run on a regular basis.
Overall, Random Forest Regression is a powerful machine learning algorithm that can be used to make predictions and classify data. However, it is important to be aware of its limitations, such as its lack of interpretability, sensitivity to hyperparameters, and computational expense.
Applying Random Forest Regression to Natural Language Processing
Random Forest Regression is a powerful machine learning technique that can be applied to Natural Language Processing (NLP). It is a supervised learning algorithm that can be used to predict the output of a given input. It is based on the concept of decision trees, which are used to make decisions based on a set of conditions.
Random Forest Regression works by creating multiple decision trees, each of which is trained on a different subset of the data. The output of each tree is then combined to form a single prediction. This approach is advantageous because it reduces the risk of overfitting, which is when a model is too closely tailored to the training data and does not generalize well to unseen data.
Random Forest Regression can be used to classify text documents, predict sentiment, and identify topics. It can also be used to identify relationships between words and phrases. For example, it can be used to identify the sentiment of a sentence by looking at the words that appear in it.
In addition, Random Forest Regression can be used to identify the most important features in a text document. This can be used to identify the topics of a document or to identify the most important words in a sentence.
Overall, Random Forest Regression is a powerful tool for Natural Language Processing. It can be used to classify text documents, predict sentiment, identify topics, and identify relationships between words and phrases. It is an effective way to reduce the risk of overfitting and to identify the most important features in a text document.
The Use of Random Forest Regression for Anomaly Detection
Anomaly detection is a process of identifying unusual patterns in data that do not conform to expected behavior. It is an important task in many areas such as fraud detection, network intrusion detection, and medical diagnosis. Random forest regression is a powerful machine learning technique that can be used for anomaly detection.
Random forest regression is an ensemble learning method that combines multiple decision trees to create a more accurate and robust model. It works by randomly selecting a subset of features from the dataset and then building a decision tree based on those features. The model is then trained on the data and used to make predictions. The predictions from each tree are then combined to form a single prediction.
Random forest regression has several advantages over other machine learning techniques for anomaly detection. First, it is able to handle large datasets with high dimensionality. This is important for anomaly detection, as it is often necessary to consider many features in order to accurately identify anomalies. Second, random forest regression is able to handle non-linear relationships between features, which is important for detecting complex patterns in data. Finally, random forest regression is able to handle missing values, which is important for datasets with incomplete information.
Random forest regression has been used successfully for anomaly detection in a variety of applications. For example, it has been used to detect fraudulent credit card transactions, network intrusions, and medical conditions. It has also been used to detect anomalies in financial markets, such as stock prices and currency exchange rates.
In conclusion, random forest regression is a powerful machine learning technique that can be used for anomaly detection. It is able to handle large datasets with high dimensionality, non-linear relationships between features, and missing values. It has been used successfully for anomaly detection in a variety of applications, including fraud detection, network intrusion detection, and medical diagnosis.
Investigating the Impact of Outliers on Random Forest Regression
Outliers are data points that are significantly different from the rest of the data points in a dataset. They can have a significant impact on the results of a regression analysis, particularly when using a Random Forest Regression (RFR) model. RFR is a powerful machine learning algorithm that is used to predict continuous values from a set of independent variables. It is a non-parametric method that is capable of handling large datasets with a high degree of accuracy.
Outliers can have a significant impact on the results of an RFR model. This is because the algorithm is based on the assumption that the data points are normally distributed. If there are outliers present in the dataset, the model may be unable to accurately predict the values of the dependent variable. This can lead to inaccurate results and a decrease in the overall accuracy of the model.
Outliers can also affect the performance of the model in terms of its ability to generalize. If the outliers are not removed from the dataset, the model may be unable to accurately predict values for new data points. This can lead to a decrease in the overall accuracy of the model.
In order to minimize the impact of outliers on an RFR model, it is important to identify and remove them from the dataset. This can be done by using various techniques such as box plots, scatter plots, and statistical tests. Once the outliers have been identified, they can be removed from the dataset and the model can be re-trained. This will ensure that the model is able to accurately predict values for new data points and will improve the overall accuracy of the model.
In conclusion, outliers can have a significant impact on the results of an RFR model. It is important to identify and remove them from the dataset in order to ensure that the model is able to accurately predict values for new data points. This will improve the overall accuracy of the model and will ensure that it is able to generalize well.
Leveraging Random Forest Regression for Feature Selection
Random Forest Regression is a powerful machine learning technique that can be used for feature selection. It is a supervised learning algorithm that can be used to identify the most important features in a dataset. It works by constructing a multitude of decision trees from randomly selected subsets of the data and then averaging the results.
The algorithm works by randomly selecting a subset of the features in the dataset and then constructing a decision tree from the data. The decision tree is then used to make predictions on the data. The predictions are then compared to the actual values in the dataset. The features that are most important in making accurate predictions are then identified.
Random Forest Regression is a powerful tool for feature selection because it is able to identify the most important features in a dataset without the need for manual feature selection. It is also able to identify non-linear relationships between features and the target variable. This makes it a powerful tool for identifying complex relationships in data.
Random Forest Regression is also a fast and efficient algorithm. It is able to quickly identify the most important features in a dataset without the need for extensive computation. This makes it a great tool for feature selection in large datasets.
Overall, Random Forest Regression is a powerful tool for feature selection. It is able to quickly identify the most important features in a dataset without the need for manual feature selection. It is also able to identify non-linear relationships between features and the target variable. This makes it a great tool for identifying complex relationships in data.
Optimizing Random Forest Regression for Improved Predictive Accuracy
Random Forest Regression is a powerful machine learning algorithm that can be used to make accurate predictions. It is a supervised learning algorithm that uses multiple decision trees to make predictions. The algorithm works by randomly selecting a subset of features from the dataset and then building a decision tree for each of the selected features. The predictions are then made by averaging the predictions of all the decision trees.
Random Forest Regression is a powerful tool for predictive modeling, but it can be improved to increase its accuracy. Here are some tips for optimizing Random Forest Regression for improved predictive accuracy:
1. Use the right number of trees: The number of trees used in the Random Forest Regression should be carefully chosen. Too few trees can lead to underfitting, while too many trees can lead to overfitting. The optimal number of trees should be determined by testing different values and selecting the one that yields the best results.
2. Tune the hyperparameters: Hyperparameters are the parameters that control the behavior of the Random Forest Regression algorithm. Tuning these parameters can help improve the accuracy of the predictions. Commonly tuned hyperparameters include the number of features used in each tree, the maximum depth of each tree, and the minimum number of samples required to split a node.
3. Use cross-validation: Cross-validation is a technique used to evaluate the performance of a model. It involves splitting the dataset into training and testing sets and then using the training set to train the model and the testing set to evaluate its performance. Cross-validation can help identify the best hyperparameters for the model and can also help identify any potential overfitting.
By following these tips, you can optimize Random Forest Regression for improved predictive accuracy. With the right tuning and optimization, Random Forest Regression can be a powerful tool for predictive modeling.
Utilizing Random Forest Regression for Time Series Forecasting
Random Forest Regression (RFR) is a powerful machine learning technique that can be used for time series forecasting. It is a supervised learning algorithm that can be used to predict future values of a time series based on past values. RFR is an ensemble method that combines multiple decision trees to create a more accurate and robust prediction model.
RFR is a non-parametric method, meaning that it does not make any assumptions about the underlying data distribution. This makes it well-suited for time series forecasting, as it can capture complex patterns in the data that may not be captured by traditional parametric methods. Additionally, RFR is robust to outliers and can handle missing values in the data.
RFR is a powerful tool for time series forecasting, as it can capture complex patterns in the data and is robust to outliers and missing values. It is also relatively easy to implement and can be used with a variety of data types. However, it is important to note that RFR is a black-box method, meaning that it is difficult to interpret the results. Additionally, it is important to tune the hyperparameters of the model to ensure optimal performance.
Analyzing the Performance of Random Forest Regression
Random Forest Regression is a powerful machine learning algorithm that is used to predict continuous values. It is an ensemble method that combines multiple decision trees to create a more accurate and stable prediction. This method is often used in applications such as predicting stock prices, sales forecasting, and predicting customer churn.
In order to analyze the performance of Random Forest Regression, it is important to consider several factors. First, the accuracy of the model should be evaluated. This can be done by comparing the predicted values to the actual values. Additionally, the model should be tested on different datasets to ensure that it is generalizable.
The next factor to consider is the speed of the model. Random Forest Regression is a computationally intensive algorithm, so it is important to ensure that it is running efficiently. This can be done by measuring the time it takes to train and test the model.
Finally, the interpretability of the model should be evaluated. Random Forest Regression is a black box algorithm, meaning that it is difficult to interpret the results. However, there are techniques such as feature importance and partial dependence plots that can be used to gain insight into the model’s behavior.
Overall, Random Forest Regression is a powerful machine learning algorithm that can be used to make accurate predictions. However, it is important to evaluate the accuracy, speed, and interpretability of the model in order to ensure that it is performing optimally.
How to Implement Random Forest Regression in Python
Random Forest Regression is a powerful machine learning algorithm that can be used to make predictions on continuous data. It is an ensemble method that combines multiple decision trees to create a more accurate and stable prediction. In this article, we will discuss how to implement Random Forest Regression in Python.
First, we need to import the necessary libraries. We will be using the Scikit-Learn library for this task. We will also need the NumPy library for numerical operations.
Next, we need to prepare the data. We will use the Boston Housing dataset for this example. This dataset contains information about the housing prices in the Boston area. We will use the features in this dataset to predict the median house price.
Once the data is ready, we can create the Random Forest Regressor. This is done by instantiating the RandomForestRegressor class from the Scikit-Learn library. We can then fit the model to the data by calling the fit() method.
After the model is trained, we can make predictions on new data. This is done by calling the predict() method. The output of this method is an array of predicted values.
Finally, we can evaluate the performance of the model by computing the mean squared error. This is done by calling the mean_squared_error() method from the Scikit-Learn library.
In this article, we discussed how to implement Random Forest Regression in Python. We used the Scikit-Learn library to create the model and the NumPy library for numerical operations. We also used the Boston Housing dataset to train and evaluate the model.
Understanding the Hyperparameters of Random Forest Regression
Random Forest Regression is a powerful machine learning algorithm that is used for both classification and regression tasks. It is an ensemble method that combines multiple decision trees to create a more accurate and robust model. The algorithm works by randomly selecting a subset of features from the dataset and then building a decision tree based on those features. The result is an ensemble of decision trees that can be used to make predictions.
The performance of a Random Forest Regression model is determined by the hyperparameters that are used to configure the model. These hyperparameters include the number of trees, the maximum depth of the trees, the minimum number of samples required to split a node, the maximum number of features used to build a tree, and the number of samples used for leaf node prediction.
The number of trees is the most important hyperparameter as it determines the complexity of the model. A higher number of trees will result in a more accurate model, but it will also increase the computational cost. The maximum depth of the trees is also important as it determines the number of levels in the tree. A deeper tree will be more accurate, but it will also increase the computational cost.
The minimum number of samples required to split a node is also important as it determines the minimum number of samples that must be present in a node before it can be split. A higher number of samples will result in a more accurate model, but it will also increase the computational cost. The maximum number of features used to build a tree is also important as it determines the number of features that can be used to build a tree. A higher number of features will result in a more accurate model, but it will also increase the computational cost.
Finally, the number of samples used for leaf node prediction is also important as it determines the number of samples that are used to make predictions at the leaf nodes. A higher number of samples will result in a more accurate model, but it will also increase the computational cost.
By understanding the hyperparameters of Random Forest Regression, it is possible to configure the model to achieve the desired accuracy and computational cost.
Comparing Random Forest Regression to Other Machine Learning Algorithms
Random Forest Regression is a powerful machine learning algorithm that is used to predict continuous values. It is an ensemble method that combines multiple decision trees to create a more accurate and stable prediction. This method is often used in applications such as predicting stock prices, sales forecasting, and predicting customer churn.
Compared to other machine learning algorithms, Random Forest Regression has several advantages. First, it is relatively easy to implement and does not require a lot of tuning. This makes it a great choice for beginners. Second, it is highly accurate and robust. It is able to handle large datasets and can handle outliers without sacrificing accuracy. Finally, it is able to handle both numerical and categorical data, making it a versatile tool for many applications.
However, Random Forest Regression also has some drawbacks. It is computationally expensive and can take a long time to train. Additionally, it is prone to overfitting, so it is important to use cross-validation to ensure that the model is not overfitting the data.
Overall, Random Forest Regression is a powerful and versatile machine learning algorithm that can be used for a variety of applications. It is relatively easy to implement and can handle large datasets and outliers. However, it is computationally expensive and can be prone to overfitting, so it is important to use cross-validation to ensure that the model is not overfitting the data.
The Benefits of Random Forest Regression for Machine Learning Prediction
Random Forest Regression is a powerful machine learning technique that can be used to make predictions about data. It is a supervised learning algorithm that uses multiple decision trees to create a more accurate and reliable prediction. Random Forest Regression is a powerful tool for machine learning prediction because it is able to handle large datasets, is robust to outliers, and is able to identify non-linear relationships.
Random Forest Regression is able to handle large datasets because it uses multiple decision trees to make predictions. Each decision tree is trained on a subset of the data, and the predictions from each tree are combined to create a more accurate prediction. This allows Random Forest Regression to make predictions on large datasets without overfitting or underfitting the data.
Random Forest Regression is also robust to outliers. Outliers are data points that are significantly different from the rest of the data. Random Forest Regression is able to identify these outliers and ignore them when making predictions. This helps to ensure that the predictions are more accurate and reliable.
Finally, Random Forest Regression is able to identify non-linear relationships in the data. This is important because many real-world datasets have non-linear relationships that cannot be captured by linear models. Random Forest Regression is able to identify these non-linear relationships and use them to make more accurate predictions.
Overall, Random Forest Regression is a powerful tool for machine learning prediction. It is able to handle large datasets, is robust to outliers, and is able to identify non-linear relationships. These features make Random Forest Regression an invaluable tool for machine learning prediction.
Conclusion
Random Forest Regression is a powerful and effective ensemble learning method for machine learning prediction. It is capable of producing accurate predictions with minimal tuning and is robust to outliers and noise. It is also relatively easy to implement and can be used for both regression and classification tasks. With its ability to handle large datasets and its ability to handle complex non-linear relationships, Random Forest Regression is an excellent choice for machine learning prediction.