Representation-learning methods enabled researchers to generate images “from scratch.” Nevertheless, video generation is still a difficult task. A recent paper on arXiv.org combines Video Textures, a video synthesis method for creating simple, repetitive videos, with current advances of self-supervised learning.

Image credit: Pxhere, CC0 Public Domain
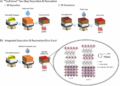
The approach synthesizes textures by resampling frames from a single input video. A deep model is trained to learn features that are spatially and temporally best suited to the input. For synthesizing the texture, the video is represented as a graph where the individual frames are nodes, and the edges represent transition probabilities. Output videos are generated by randomly traversing edges with high transition probabilities.
In one of the applications, a video is generated from a source video with associated audio and new conditioning audio. The approach outperforms previous methods on perceptual studies.
We introduce a non-parametric approach for infinite video texture synthesis using a representation learned via contrastive learning. We take inspiration from Video Textures, which showed that plausible new videos could be generated from a single one by stitching its frames together in a novel yet consistent order. This classic work, however, was constrained by its use of hand-designed distance metrics, limiting its use to simple, repetitive videos. We draw on recent techniques from self-supervised learning to learn this distance metric, allowing us to compare frames in a manner that scales to more challenging dynamics, and to condition on other data, such as audio. We learn representations for video frames and frame-to-frame transition probabilities by fitting a video-specific model trained using contrastive learning. To synthesize a texture, we randomly sample frames with high transition probabilities to generate diverse temporally smooth videos with novel sequences and transitions. The model naturally extends to an audio-conditioned setting without requiring any finetuning. Our model outperforms baselines on human perceptual scores, can handle a diverse range of input videos, and can combine semantic and audio-visual cues in order to synthesize videos that synchronize well with an audio signal.
Research paper: Narasimhan, M., Ginosar, S., Owens, A., Efros, A. A., and Darrell, T., “Strumming to the Beat: Audio-Conditioned Contrastive Video Textures”, 2021. Link: https://arxiv.org/abs/2104.02687